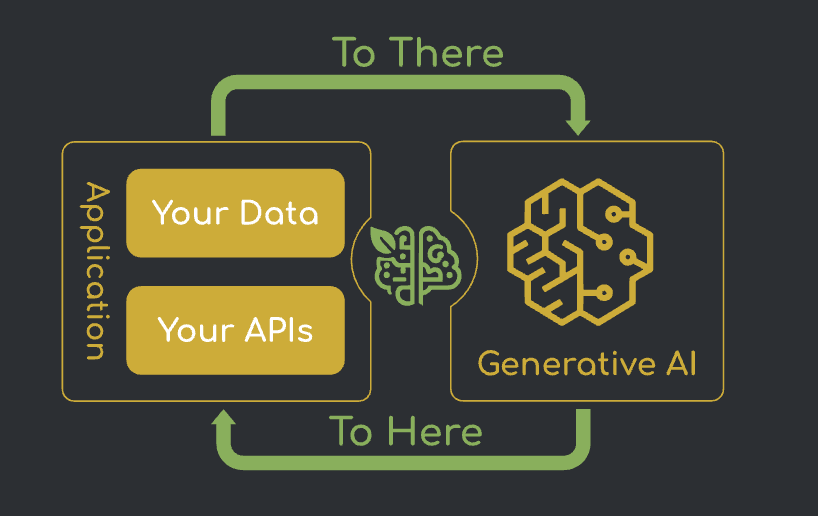
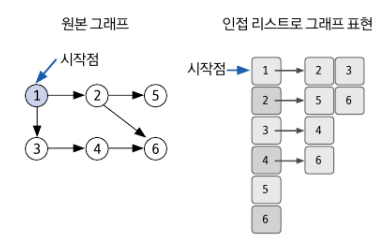
Web 개발부터 소프트웨어 엔지니어링 전반을 다룹니다.
#웹개발 #Java #Spring #DevOps #AI
- github: https://github.com/HSRyuuu
- contact: happyhsryu@gmail.com
- github: https://github.com/HSRyuuu
- contact: happyhsryu@gmail.com