
카르케시안 곱(Cartesian Product) 란?
Cartesian 곱은 2개의 테이블을 Join 할 때 모든 조합의 데이터를 생성하는 곱집합을 말한다.
예를 들면 User를 참조하고 있는 Order 3개, Payment 5개가 있을 때, 총 15개의 결과가 나온다.
아래(더 보기)는 카르테시안 곱을 처음 보는 분들을 위한 쿼리 예제입니다.
app_user
SELECT * FROM app_user u
where id = '4a421c1c-8df2-4ef2-845d-07d9a216c114';
orders
SELECT * FROM orders
where user_id = '4a421c1c-8df2-4ef2-845d-07d9a216c114';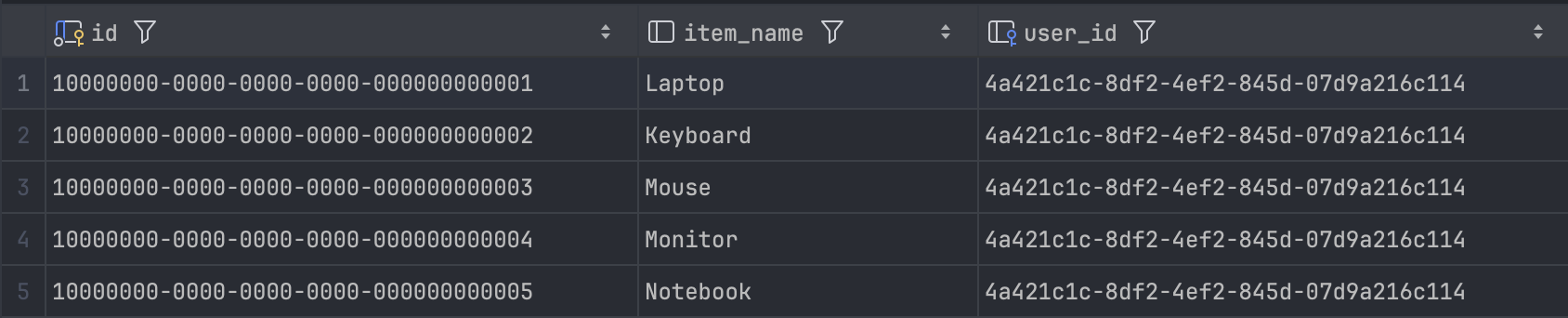
payment
SELECT * FROM payment
where user_id = '4a421c1c-8df2-4ef2-845d-07d9a216c114';

JOIN 결과
SELECT u.id as "user_id",
u.name,
o.item_name,
p.method
FROM app_user u
left join orders o on o.user_id = u.id
left join payment p on p.user_id = u.id
where u.id = '4a421c1c-8df2-4ef2-845d-07d9a216c114';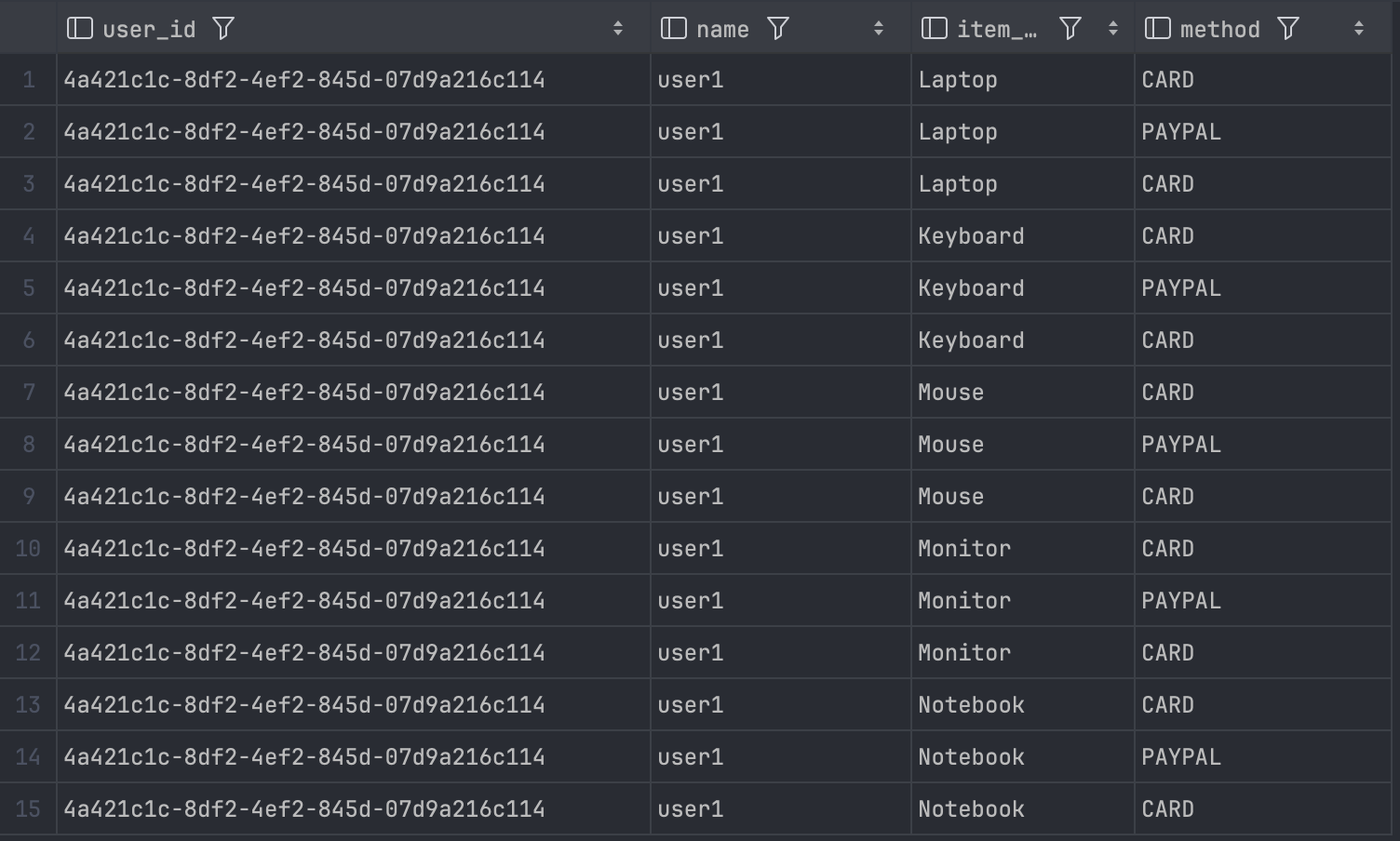
JPA에서의 카르테시안 곱 문제 발생
JPA에서는 아래와 같은 상황에서 카르테시안 곱 문제가 발생할 수 있다.
- @OneToMany에서 fetch join을 사용할 때
- 여러 컬렉션 필드를 동시에 fetch join 할 때
- 단일 쿼리에서 중복된 엔티티를 포함하게 될 때
이때 발생하는 문제
- 결과 데이터 중복
- 예상보다 많은 tuple 조회
- Hibernate 내부에서 중복 제거 시 성능 저하
-> Hibernates는 중복 제거를 위해 distinct + 내부 hash 처리를 한다.
-> 데이터가 많아지게 되면 느려진다.
해결 방법
- Set 사용: @OneToMany 매핑 시 List 대신 Set을 사용하면 중복된 tuple 처리 시 Hibernate가 최적화한다.
- fetch join 사용 주의: 컬렉션 필드에서는 fetch join을 주의해서 사용해야 한다.
- 쿼리 분리: 연관된 컬렉션은 별도 쿼리로 조회 (BatchSize, Dto 조회 등)
-- fetch join (안전한 방식)
select u from AppUser u join fetch u.group -- group은 단건이라 안전
-- 위험한 방식
select u from AppUser u join fetch u.payments -- ❌ payments가 여러 개면 곱 발생예제 Entity
AppUser
@Entity
@Table(name="app_user")
public class AppUser {
@Id
private UUID id;
private String name;
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Order> orders = new HashSet<>();
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Payment> payments = new HashSet<>();
// ❌ Bad Example
// @OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
// private List<Order> orders = new ArrayList<>();
//
// @OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true, fetch = FetchType.LAZY)
// private List<Payment> payments = new ArrayList<>();
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "group_id")
private UserGroup group;
}
Order
@Entity
@Table(name = "orders")
public class Order {
@Id
private UUID id;
private String itemName;
private int quantity;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private AppUser user;
}
Payment
@Entity
@Table(name = "payment")
public class Payment {
@Id
private UUID id;
private String method; // e.g., CARD, PAYPAL
private LocalDateTime createdAt;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private AppUser user;
}
JPA에서의 Cartesian Product 문제
JPA에서 두 개 이상의 컬렉션(List)을 fetch join으로 동시에 조회하면,
Hibernate는 이를 처리할 수 없어 MultipleBagFetchException을 발생시킨다.
이는 내부적으로 Cartesian Product(데이터 곱집합) 문제가 발생하기 때문이다.
여기서 "Bag"은 JPA에서 내부적으로 List 형식의 Collection을 다루는 단위이다.
Bag은 List와 유사하게 중복된 요소를 포함할 수 있지만, 순서를 보장하지 않는 클래스? 자료구조?이다.
이는 Java Collection Framework에 포함되어있지 않고, Hibernate에서만 사용하는 용어이다.
아래 Hibernate 소스코드에서 중복을 허용하고, 순서를 보장하지 않는 List 형태의 데이터를 "Bag"으로 다루고 있는 것을 확인할 수 있다.
- org.hibernate.mapping.Bag 클래스
- org.hibernate.annotations.Bag 어노테이션
- org.hibernate.boot.model.source.internal.hbm.ModelBinder 클래스
따라서 여러 개의 Entity를 동시에 fetchJoin 할 때 발생하는 Cartesian Product 문제를 해결하지 못하여 MultipleBagFetchException이 발생하게 되는 것이다.
간단한 해결책은 중복제거가 안돼서 발생하는 문제니까 중복체거를 되는 Set을 쓰면 된다.
정답은 이미 정해져 있다. "그냥 List 말고 Set을 사용해서 중복을 제거해라"
문제 상황 - JPQL
// User Entity Class
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Order> orders = new ArrayList<>();
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private List<Payment> payments = new ArrayList<>();@Repository
public interface UserRepository extends JpaRepository<AppUser, UUID> {
@Query("""
SELECT u
FROM AppUser u
LEFT JOIN FETCH u.orders
LEFT JOIN FETCH u.payments WHERE u.name = :name
"""
)
Optional<AppUser> findWithOrdersAndPaymentsByName(@Param("name") String name);
}
아래 코드 실행 시 에러 발생
AppUser user = userRepository.findWithOrdersAndPaymentsByName(userName).orElseThrow();
동시에(한 번에) 여러 개의 bags를 fetch 할 수 없습니다.라는 내용의 에러가 발생한다.
문제 상황 - QueryDsl
QueryDsl에서 fetchJoin() 시에도 마찬가지다. UserEntity는 위와 같다.
@RequiredArgsConstructor
@Repository
public class CustomUserRepository {
private final JPAQueryFactory queryFactory;
QAppUser user = QAppUser.appUser;
QUserGroup group = QUserGroup.userGroup;
QOrder order = QOrder.order;
QPayment payment = QPayment.payment;
public Optional<AppUser> findByName(String name) {
AppUser appUser = queryFactory
.selectFrom(user)
.leftJoin(user.orders, order).fetchJoin() // multiple fetch join
.leftJoin(user.payments, payment).fetchJoin() // multiple fetch join
.where(user.name.eq(name))
.fetchFirst();
return Optional.ofNullable(appUser);
}
// ...
}
이번에도 아래 코드 실행 시 동일한 에러가 발생한다.
AppUser user = customUserRepository.findByName("user1").orElseThrow();
두 가지 경우 모두 단순히 UserEntity의 필드 orders와 payments의 자료구조를 Set으로 바꾸기만 해도 해결된다.
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Order> orders = new HashSet<>();
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
@OrderBy("createdAt desc")
private Set<Payment> payments = new LinkedHashSet<>();해결 방법
방법 1: Set으로 Mapping
Set으로 매핑하는 게 기본 권장 사항이다.
조회 후 Entity로 데이터를 매핑하는 과정에서 Set 자료구조에 의해 중복을 제거할 수 있게 된다.
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Order> orders = new HashSet<>();방법 2: fetch join은 한 번에 하나만 사용
여러 컬렉션을 동시에 fetch join 하지 않고 꼭 필요한 관계만 하나씩 fetch join 한다.
나머지는 @BatchSize 또는 지연로딩 전략으로 최적화한다. 여러 개의 Collection을 조회하기 위한 상황에서의 해결책이다.
그러나 1:N 관계에서 연관관계의 주인이 N인 경우에는 여러 개를 fetch join 해도 상관없다.
방법 3: DTO Projection 방식 사용
전체 Entity를 조회하지 않고, 필요한 필드만 DTO로 조회하는 방법이다.
그러나 이 방식은 조회의 목적이 컬렉션 형태의 데이터가 필요한 경우에는 해당하지 않는다.
따라서 그냥 Set으로 매핑하면 될 것 같다.
추가 조건: 순서 유지를 위한 LinkedHashSet
LinkedHashSet은 삽입 순서는 유지하지만, 중복은 허용하지 않는 자료구조이다.
만약 필요한 컬렉션 형태의 데이터의 순서가 중요하다면 LinkedHashSet을 사용해도 좋다.
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
@OrderBy("quantity asc")
private Set<Order> orders = new LinkedHashSet<>();@OrderBy 어노테이션으로 정렬 조건을 지정해 줄 수 있다.
이 어노테이션이 있을 경우, Query에 Order By 절을 추가하지 않아도 JPA가 SQL에 정렬 조건을 자동으로 추가해 준다.
조회 후 Java Collection에서 정렬하는 걸로 예상했으나, SQL에 정렬 조건을 추가해준다고 한다.
그럼 JPA에서는 왜 내부적으로 PK를 가지고 동등성 비교를 해서 중복제거를 하고 List에 넣어주면 되는 건데, 왜 Exception을 발생시키냐?
-> 답변 1: 동등성 비교 후 List에 넣으려면 각 모든 List에 add 하기 전에 contains()와 같은 메서드를 실행시켜야 하는데,
각 탐색에 O(n)이 소요되므로 리소스가 너무 크다.
-> 답변 2: 그냥 Set 쓰면 되는데 왜 굳이?
-> 답변 3: LinkedHashSet 쓰면 순서 보장도 되는데 왜 굳이?
실제 문제 발생 상황 및 문제 해결
위에서 다뤘던 것처럼 이런 Cartesian 곱 발생 상황에서 여러 개를 fetchJoin 하면 MultipleBagException이 발생한다.
그래서 딱히 예상치 못한 개수의 tuple이 반환되는 문제를 만나긴 어렵다.
그러나 에러가 발생하지 않고, 중복된 데이터가 조회되는 경우가 있다. 에러가 발생하면 원인을 찾기 위한 접근 시작점이라도 알 수 있지만, 그렇지 않고 정상 반환이 되면 이유조차 찾기 어려웠을 것이다.
실제로 실무에서 하나의 Entity에 연관된 여러 개의 컬렉션 형식의 필드를 조회하고, 해당 컬렉션의 순서를 보장해야 하는 상황에서 이런 문
제를 만났다.
상황은 아래와 같다.
- 조건 1: order1과 order2를 주문
- 조건 2: 결제방법이 PAYPAL
- 조건 3: Limit 5
Bad Example
주문 방법이 paymentMethods에 속하거나, 주문한 상품 명이 orderItemNames에 속하는 User를 n 명 조회하는 상황
public List<UserDto> searchUserBadExample(
List<String> paymentMethods, List<String> orderItemNames, Pageable pageable) {
return queryFactory
.select(Projections.fields(
UserDto.class,
user.id,
user.name.as("username")
))
.from(user)
.leftJoin(user.orders, order)
.leftJoin(user.payments, payment)
.where(order.itemName.in(orderItemNames).or(payment.method.in(paymentMethods)))
.limit(pageable.getPageSize())
.offset(pageable.getOffset())
.fetch();
}test code
@Test
@Transactional
void badExample() {
List<String> paymentMethods = List.of("PAYPAL");
List<String> orderItemNames = List.of("order1", "order2");
PageRequest pageRequest = PageRequest.of(0, 5);
List<UserDto> users = customUserRepository
.searchUserBadExample(paymentMethods, orderItemNames, pageRequest);
for(UserDto user : users) {
System.out.println(user.toString());
}
}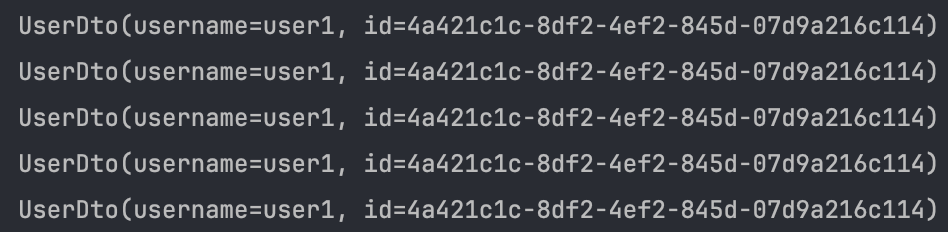
User를 기준으로 최대 5명의 유저가 조회되길 기대했으나 똑같은 user가 5개 조회되었다.
원인은 내부적으로 Cartesian 곱이 발생한 상태로 UserDto 여러 개가 반환되었기 때문이다.
Limit를 크게 늘려보자.

의도한 건 User가 3명만 조회되었어야 한다. 그러나 쿼리 결과 tuple이 13가 반환된 것을 중복제거하지 않고 반환되어서 UserDto가 13개 조회되었다.
이 상황에서는 User.orders와 같이 필드로 접근하는 게 아니라, 쿼리 결과를 단순히 DTO에 매핑해 주는 상황이라 Users.orders 필드가 List로 선언되어 있어도 MultipleBagFetchException은 발생하지 않는다.
Good Example
쿼리를 아래와 같이 바꿔서 해결할 수 있다.
Id를 먼저 distinct 하여 조회해서 idList를 뽑아내고, 실제 쿼리에는 where 조건에 in 절로 idList를 포함시시키는 방법이다.
이렇게 하면 pagination에도 유리하고, 의도한 대로 User를 기준으로 조회할 수 있게 된다.
public List<UserDto> searchUser(
List<String> paymentMethods, List<String> orderItemNames, Pageable pageable) {
List<UUID> userIds = queryFactory.select(user.id)
.distinct()
.from(user)
.leftJoin(user.orders, order)
.leftJoin(user.payments, payment)
.where(order.itemName.in(orderItemNames).or(payment.method.in(paymentMethods)))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
if(userIds.isEmpty()) {
return List.of();
}
return queryFactory
.select(Projections.fields(
UserDto.class,
user.id,
user.name.as("username")
))
.from(user)
.where(user.id.in(userIds))
.fetch();
}
test code
@Test
@Transactional
void goodExample() {
List<String> paymentMethods = List.of("PAYPAL");
List<String> orderItemNames = List.of("order1", "order2");
PageRequest pageRequest = PageRequest.of(0, 5);
List<UserDto> users = customUserRepository
.searchUser(paymentMethods, orderItemNames, pageRequest);
for(UserDto user : users) {
System.out.println(user.toString());
}
}
해당 방법은 pagination 처리를 할 때 유용하게 사용하는 방법이다.
정리
- 카르테시안 곱(Cartesian Product)은 여러 컬렉션을 fetch join할 때 발생할 수 있으며,
예상보다 많은 중복된 튜플을 반환하는 문제가 생긴다. - JPA에서 MultipleBagFetchException은 List 기반의 @OneToMany 관계를 여러 개 동시에 fetch join할 때 발생하며,
이는 내부적으로 곱집합을 처리하지 못하기 때문이다. - Set으로 매핑하면 중복을 제거할 수 있어 가장 간단하고 효과적인 해결책이다. 순서가 필요한 경우 LinkedHashSet과 @OrderBy를 함께 사용한다.
- DTO Projection 방식이나 ID를 먼저 distinct 후 조회하는 전략은 Pagination과 성능 최적화에 유리하다.
- fetch join은 필요한 경우에 한정해서 하나씩 사용하고, 나머지는 @BatchSize 등으로 분리 조회하는 전략을 고려한다.
참고 자료
https://www.baeldung.com/java-hibernate-multiplebagfetchexception
'JPA & QueryDSL' 카테고리의 다른 글
| [JPA] JPA 복합키 Entity Mapping @IdClass / @EmbeddedId (0) | 2025.03.25 |
|---|---|
| [QueryDSL] BooleanExpression을 이용한 WHERE 조건 표현식 (0) | 2025.03.07 |
| [JPA / Spring] JPQL을 이용해서 Entity가 아닌 DTO를 반환하는 방법 (0) | 2024.05.07 |
| [JPA] 연관 관계 매핑 - @ManyToMany (0) | 2023.10.06 |
| [JPA] 연관관계 매핑 (1) | 2023.10.06 |